

| Python code for ARM |
|---|
| Cleaned data |
| Python Code to ARM |
In this section I will use ARM method to find out which two methods will occur together the most.
ARM also called Association rule mining. As you can see from the name, it simply helps discover relationships between seemingly independent relational databases or other data repositories. Which helps identify the dependencies between two data items. Based on the dependency, it then maps accordingly so that it can be more profitable. Most machine learning algorithms work with numeric datasets and hence tend to be mathematical. However, association rule mining is suitable for non-numeric, categorical data. And this is different from all the previous method that I'm using.
So what metrics that are in the ARM?
Support: Sup(A, B): Measures How often item-set with A and items in B occur together relative to all other transactions.
Confidence: Conf(A, B) Measures how often items in A and items in B occur together, relative to transactions that contain A.
Lift: The lift of a rule is the ratio of the observed support to that expected if X and Y were independent. And when the lift result is 1 it means two factors are independent. If the lift result is less than 1 it means two factors are negatively related. If the lift result is greater than 1 it means two factors are positively related.
And there are mainly three different types of algorithms that can be used to generate associate rules in data mining.
Apriori Algorithm: Apriori algorithm identifies the frequent individual items in a given database and then expands them to larger item sets, keeping in check that the item sets appear sufficiently often in the database.
Eclat Algorithm: ECLAT algorithm is also known as Equivalence Class Clustering and bottomup. Latice Traversal is another widely used method for associate rule in data mining. Some even consider it to be a better and more efficient version of the Apriori algorithm.
FP-growth Algorithm: Also known as the recurring pattern, this algorithm is particularly useful for finding frequent patterns without the need for candidate generation. It mainly operates in two stages namely, FP-tree construction and extract frequently used item sets.
And here I use Apriori Algorithm to solve the problem.
Here is the result, since I have too many variables here And the plot looks too crowded. So I also use a table to show the result. And the lift for the top 10 are all greater than 1 which means it all are positive related. And the most related lift are the CITALOPRAM and ESCITALOPRAM which is about 14.622541. And the second method is CITALOPRAM and SERTRALINE which is about 12.202691. The third is CITALOPRAM and ESCITALOPRAM which is about 11.136821. And fourth is ESCITALOPRAM and SERTRALINE which is about 10.900598.
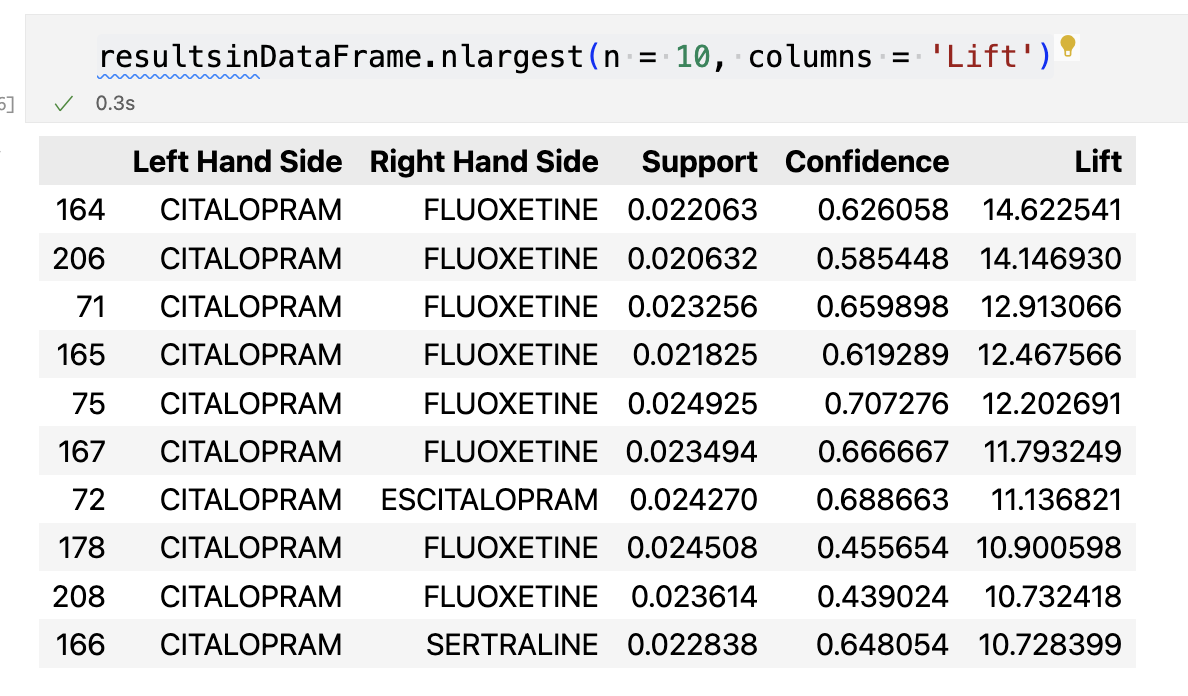
Since CITALOPRAM and ESCITALOPRAM have the most support value, confidence value and also lift value. We can conclude that CITALOPRAM and ESCITALOPRAM use together the most among all the other drug use.