



Since we have a lot of data in our dataset, I will delete some columns that are not very important. First, I deleted the first column, which is the number of the hospital where the record occurred.Then I took out the age and gender from the description column, and formed two new columns of data.Then the remaining descriptions were divided into sections, with each description number corresponding to the first few symptom of each person. The blank space will be changed to the value of NA, as this proves that the corresponding population did not receive the treatment.
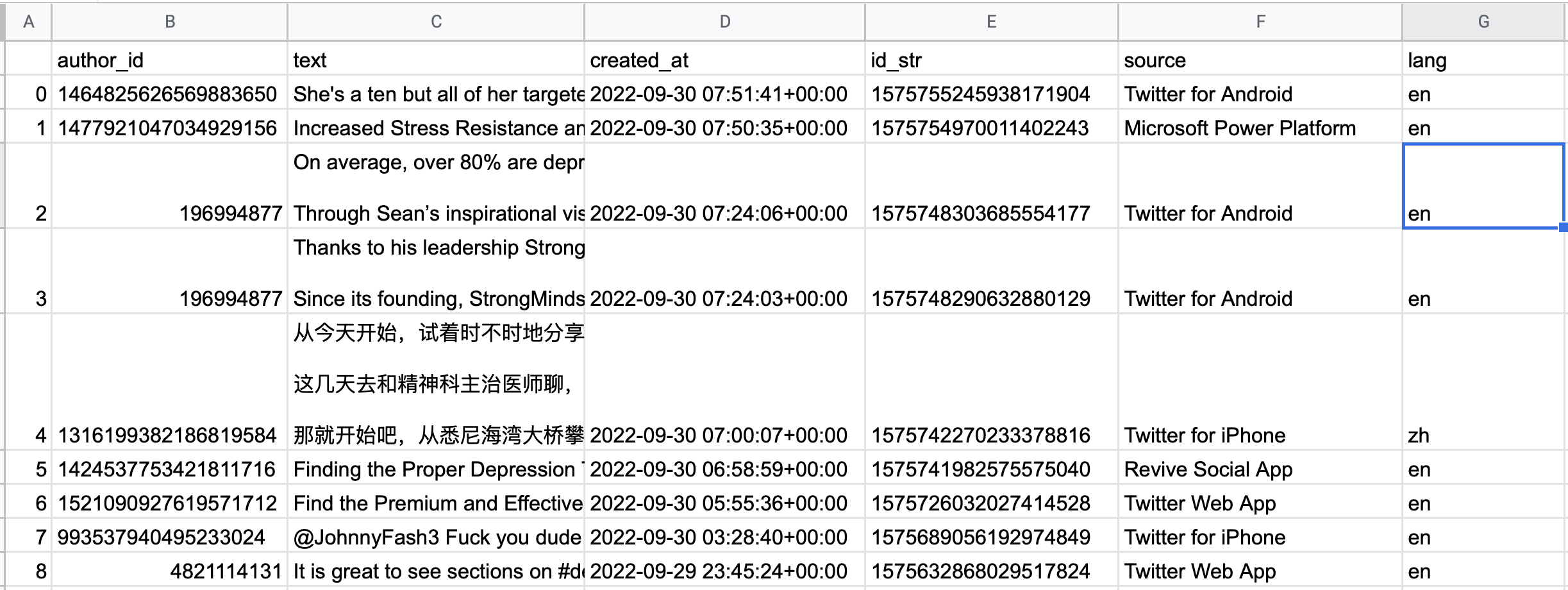


I first remove some not necessary columns like 'Unnamed: 0','id_str' and 'created_at', because it do not related to my question about which treatments are effective for Depression. And then I check if there are any columns have Null value. And we don't have any null value rows, so I don't need to do anything about it. Next step is remove punctuations, I check what words are included as punctuations, for example '!"#$%&\'()*+,-./:;=>?@[\\]^_`{|}~'. So there words should be removed. Third, I tokenize the sentence which covert those sentence into a list of words. Then I remove Stopwords, for example the words like 'the', 'a','an' which will help to visualize the data. Then I stemming the words which stemming is a technique used to extract the base form of the words by removing affixes from them.
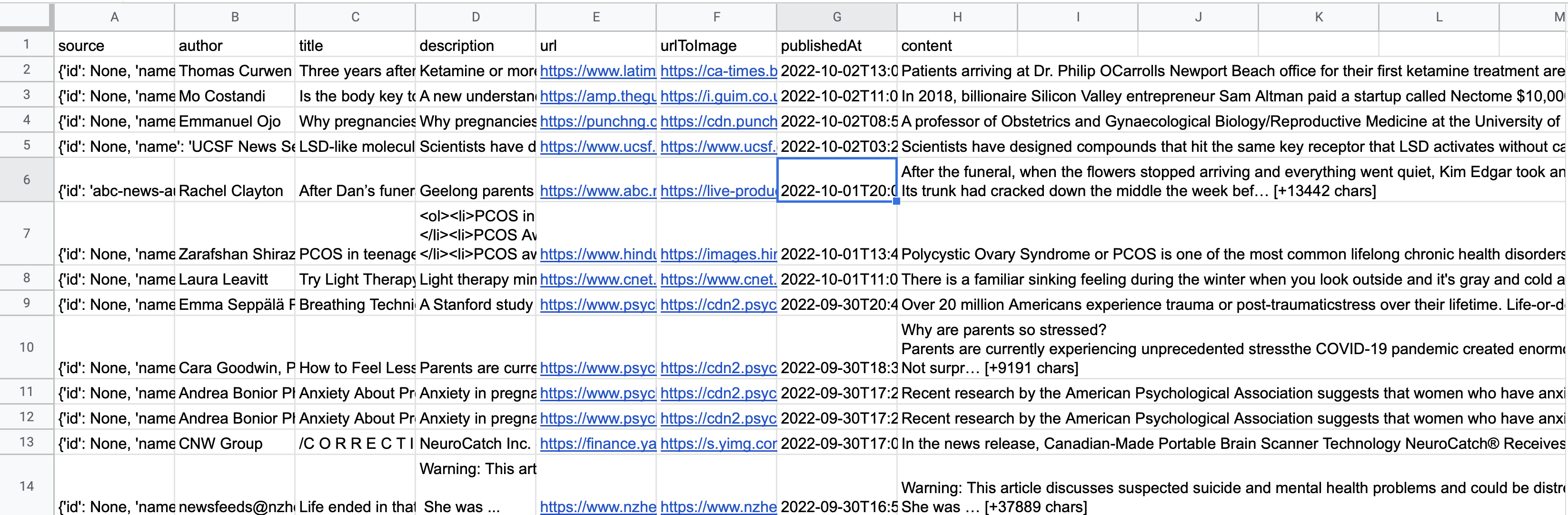
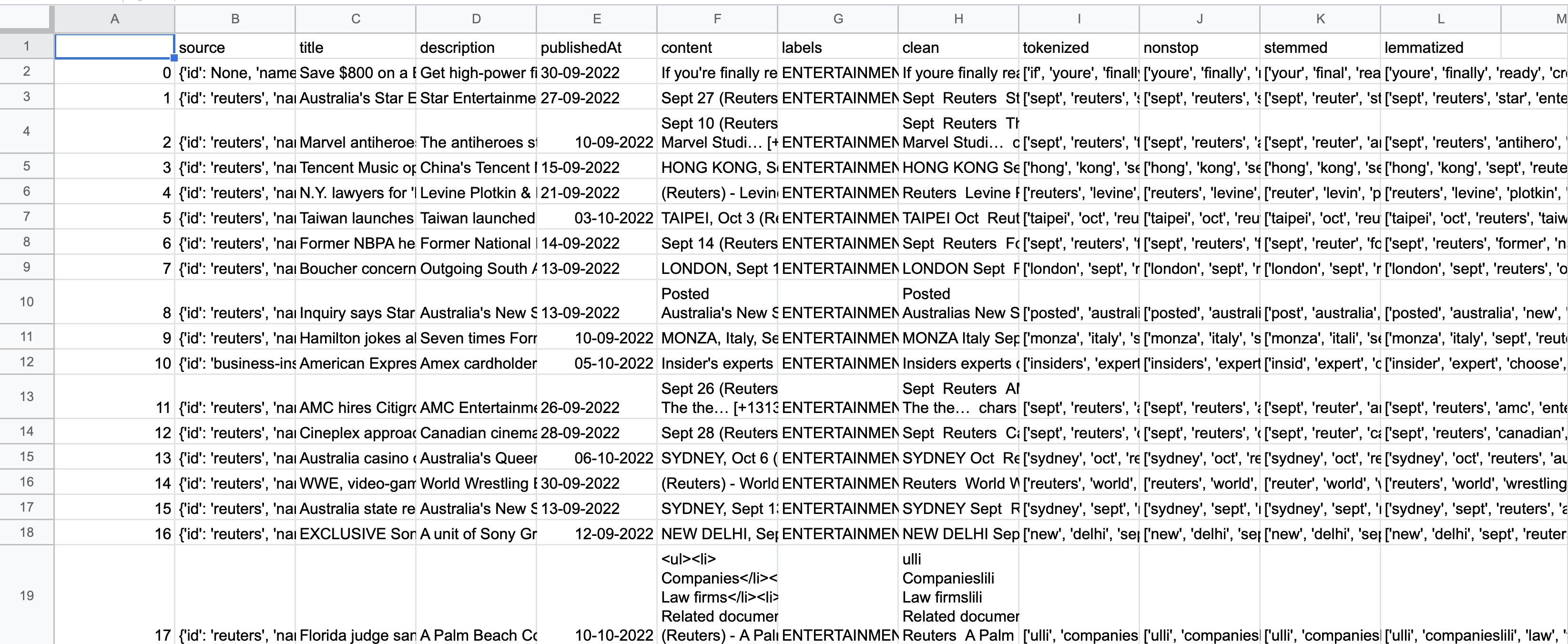
I first remove some not necessary columns like 'Unnamed: 0'because it do not related to my question about which treatments are effective for Depression. And then I check if there are any columns have Null value. And we don't have any null value rows, so I don't need to do anything about it. Next step is remove punctuations, I check what words are included as punctuations, for example '!"#$%&\'()*+,-./:;=>?@[\\]^_`{|}~'. So there words should be removed. Third, I tokenize the sentence which covert those sentence into a list of words. Then I remove Stopwords, for example the words like 'the', 'a','an' which will help to visualize the data. Then I stemming the words which stemming is a technique used to extract the base form of the words by removing affixes from them. This is the step that are about the same as python Tweet clean process. Since they both are text data.