
| Python code for Clustering |
|---|
| Cleaned data |
| Python Code to clustering(including k- means, DBSCAN, and Hierarchical clustering) |
I first set the 4 categories as the target and the feature X is the four categories (young women, old women, young men, old men).I am trying to classify each category using 3 methods K-means, DBSCAN, and Hierarchical clustering. And see which method provide the answer that are closest to my original setting.
So what is Clustering overall? Clustering is the task of dividing a population or data points into groups such that data points in the same group are more similar than those in other groups. Simply put, its purpose is to isolate groups with similar characteristics and assign them to clusters. And in this section we are going to use Kmeans, DBSCAN and Hierarchical clustering to solve the problem.
Kmean:We first define a target number k, which is the number of centroids you need in your dataset. The 'means' refers to the centroid. The centroid is an imaginary or real location representing the center of the cluster. So, combine them all together, the K-means algorithm identifies k number of centroids, and then allocates every data point to the nearest cluster, while keeping the centroids as small as possible. How Kmean work? It first starts with a first group of randomly selected centroids, which are used as the beginning points for every cluster, and then performs several calculations to optimize the positions of the centroids.When The centroids become stabilized that there is no change in their values because the clustering has been successful or the defined number of iterations has been achieved. Then the optimization will stop.
DBSCAN:DBSCAN also refer to Density-based spatial clustering of applications with noise. DBSCAN can perform very well on high density of observations given a dataset compared to areas of the data that are not very dense with observations. It first starts by dividing the data into n dimensions. After that it will begin from a random point and count how many other points are nearby. After continuing this process until no other data points are nearby, then it will look to form a second cluster. Although DBSCAN is great at separating high density clusters from low density clusters, DBSCAN struggles with clusters of similar density and also high dimension dataset.
Hierarchical clustering:Hierarchical clustering can group data into a tree of clusters. It first defines two clusters that are closest together and then merge the two most similar clusters. We will continue these steps until all the clusters are merged. And the result will usually present by a graph called Dendrogram which is a tree-like diagram that statistics the sequences of merges or splits.
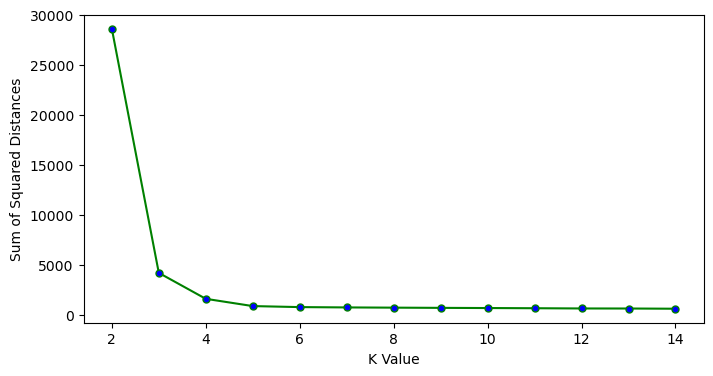
For the result of Kmean it shows that k = 4 is the optimal here. Which means it gives 4 clusters.
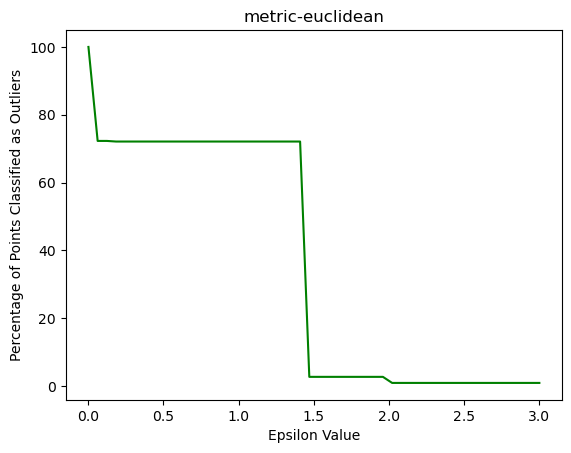
In DBSCAN, there are 2 main parameters that can be adjusted, 'epsilon' (eps) and 'min_samples'. A good 'min_samples' number is two times the number of features (columns). We have 83 features so 'min_samples' value will be 83*2 = 166. The 'elbow' forms somewhere around epsilon = 1.5 for cosine metric.
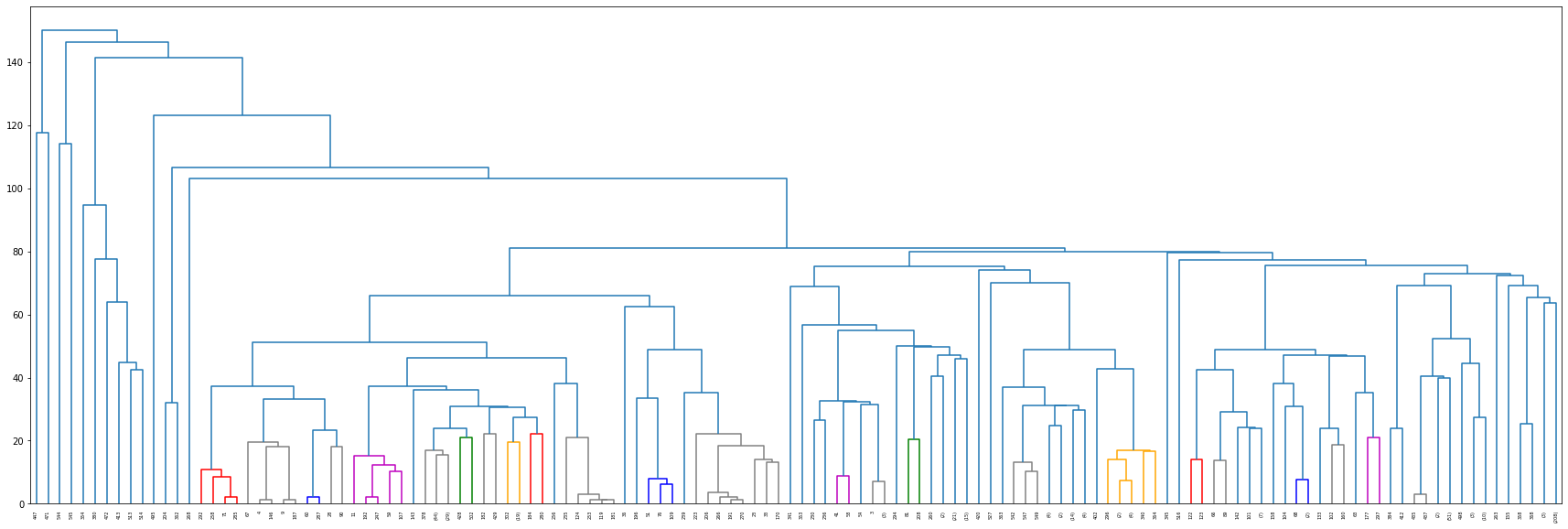
For the result of Hierarchical clustering, it gives 7 clusters.
We found that Kmeans is the best for this medicine as its giving 4 cluster. The original data also had 4 classes. DBSCAN with the set parameters does not perform well for this dataset because it can only give 2 cluster. And Hierarchical Clustering is giving 7 cluster which is too much. Kmeans is easy to build and it's the best performing here, we can check its performance by passing different value of k and based on elbow method we can choose best k